Micro services or API layer design the most non avoidable design patterns, any product can adopt to evolve into more robust design. It is interesting to look at different patterns from rest or aggregated api with graphql as BFF or server less and working with cloud and Messaging ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
In this articles we
will go though Async programming and request response from third party api and
aggregate data and send it back to service. Here is one example where we get
response from api and this will be executed around 200 times per one client
request. So it is important to see how it is possible to achieve response for
this client request with in 5 sec. time.
One way is to span 200
threads and get response for this that will be quick. Let us see how many other
options which could be memory optimized and time optimized and how these kind
of batch processing can be hosted using latest available technologies.
private async
Task<List<APIResponse>> GetData(List<string> names)
{
List<APIResponse> data = new
List<APIResponse>();
try
{
string param = "";
foreach (string name in names)
{
HttpResponseMessage response =
await
client.GetAsync("https://api.genderize.io?" + param +
"&apikey=<APIKEY>");
var content = await
response.Content.ReadAsStringAsync();
dynamic viewdata = JsonConvert.DeserializeObject<dynamic>(content);
foreach (var d in viewdata)
{
var value = new APIResponse();
value.name = d.name;
value.gender = d.gender;
data.Add(value);
}
//var returnValue =
JsonConvert.DeserializeObject<APIResponse>(content);
}
return data;
}
Few important design principles for above problem could be
1. Above function should be
executed in parallel and should not be an blocking synchronous call,.Async
should be used .
2. \Number of threads as
given about are 200, it is not good design to loop though N number of
times and create N number of threads. Most of the OS will have limitation on
spawning resource either it is threads or file handlers. So above parallel
execution should be divided into batches and combine the result of each batch
and return response.
3. The complete processing
can be done on a independent infra like serverless apps or lamda as it is not
using any data from the application. which can help to scale up the
corresponding hardware if required.
Design Patterns
Worker pool/Job queue Pattern: The worker pool pattern is simple and most widely used concurrency pattern for distributing multiple jobs or patterns to multiple workers.
In above image jobs are stored in a data structure say Job queue and pool of worker threads which will get job based on scheduler. If we can access multiple cores it is possible to process them parallel like Golang.
Monitor
Pattern: n number
of threads waiting on some condition to be true , if the condition is not true
those threads need to be in sleep state and pushed to wait queue, and they have
to be notified when condition is true.
Double
Checked locking: for creating concurrent objects
(ex: singleton pattern)
Barrier
Pattern: all concurrently
executing threads must wait for others to complete and wait at a point called
Barrier
Reactor Pattern: In an event driven
system, a service handler accepts events
from multiple incoming requests and demultiplexes to respective non
blocking handlers.
Let us look at
few solutions to execute above function and get response.
Here is basic solution where it can create thread and there is mechanism
in c# to control number of threads at a time can be created. which is fair
enough and we can fine tune maxdegreeofparallelism according to resource and
response time required. This concept is thread pooling and
available in spring batch settings and other programming language as
well.
Here is one
configuration used in a spring batch job
· core-pool-size:
20 max-pool-size: 20
· throttle-limit:
10
Here is
example from Phython for doing similar task i.e make multiple requests
simultaneously, use asyncio.gather:
Consider this example:
Grandmaster Judith Polgar is at a chess convention. She plays against 24
amateur chess players. To make a move it takes her 5 seconds. The opponents
need 55 seconds to make their move. A game ends at roughly 60 moves or 30 moves
from each side. (Source: https://github.com/fillwithjoy1/async_io_for_beginners)
Synchronous version
import
time
def play_game(player_name): for move in range(30): time.sleep(5) # the champion
takes 5 seconds to make a move print(f"{player_name} made
move {move+1}") time.sleep(55) # the opponent
takes 55 seconds to make a move
if __name__ == "__main__": players = ['Judith'] + [f'Amateur{i+1}'
for i in range(24)] for player in players: play_game(player)
Asynchronous version
import
asyncio
async def play_game(player_name): for move in range(30): await asyncio.sleep(5) # the
champion takes 5 seconds to make a move print(f"{player_name} made
move {move+1}") await asyncio.sleep(55) # the
opponent takes 55 seconds to make a move
async def play_all_games(players): tasks =
[`asyncio.create_task`(play_game(player)) for player in players] await `asyncio.gather`(*tasks)
if __name__ == "__main__": players = ['Judith'] + [f'Amateur{i+1}'
for i in range(24)] asyncio.run(play_all_games(players))
In the synchronous version,
the program will run sequentially, playing one game after another. Therefore,
it will take a total of 24 * 60 * 60 = 86,400 seconds
(or 1 day) to complete all the games.
In the asynchronous version,
the program will run concurrently, allowing multiple games to be played at the
same time. Therefore, it will take approximately 60 * 5 = 300 seconds (or 5 minutes) to complete all the games, assuming that there are
enough resources available to handle all the concurrent games.
Create separate backend services to be consumed by specific
frontend applications or interfaces. This pattern is useful when you want to
avoid customizing a single backend for multiple interfaces. This pattern was
first described by Sam Newman.
Advantages of graphQL as BFF
One of the leading technology used to implementation for BFFs
is GraphQL. Let us look at the advantages and important features of this
technology.
·Rest vs Graphql API: In Rest single end point
pairs with a single operation. If different response needed new end point is
required. GraphQL allows you to pair with single end point with multiple data
operations .
oThis
results in optimizing traffic bandwidth.
oFixes the issue of under-fetching /
over-fetching.
·Uses single end point . Http requests from client
will be simple implementation.
·N+1 problem solution for aggregating data from different
microservices.
·Pagination : The GraphQL type system allows for
some fields to return list of values which help in implementation of pagination
for API response.
·Error Extensions: GraphQL there is a way to
provide extensions to the error structure using extensions.
Few issues / anti patterns in GraphQL schema design need
proper design and can be avoided using best practices recommended for this
pattern. Here are few of them
·Nullable fields: In GraphQL every field is
nullable.
·Circular reference . It can result in massive data
in response.
·Allowing invalid data and using custom scalar
to overcome this issue.
we can see GraphQL
helps in aggregating multiple back end services /sources and providing one
interface to each client only the data it needs. That makes Graphql easy to
build BFF.
Use case 1:In
talash.azurewebsites.netImages, video
data coming from two different micro services and TalashBFF will aggregate both
services and return as GraphQL end point response. Which is basically at client
just need to mention required query no need to look into details of rest end points for image and Video.
Implementation Details:
Graphql server will deliver post end point with the
following two query from client side.
As shown above data.imagezes is resolver which will fetch data from http
end point and return Image type which is graph ql type has url and member.
Similar query and types designed for video Data and retrieved
though the another resolver.
So In above example it is possible to get data from two different
sources from same Graphql end point and the number of fields retrieved can change and not tightly coupled to the client
implementation. Apollo angular client
used to consume GraphGL end point.
All major advantages can be achieved with above simple implementation.
We can look in to more complex examples below.Use
case 2: In above example to implement grpahql server and end point graphql-dotnetproject used which is most
popular implementation of dotnet based graphql server. There are many
implementations available for each programming language.
Hasuratakes the known entity that is Postgres and turns it into
a magic GraphQL end point locked down by default. Postgres and GraphQL are both
pretty known entities. GraphQL less so of a known entity but it's gaining
popularity.
AWS AppSyncfeatures
·Simplified
data access and querying, powered by GraphQL
·Serverless WebSockets for GraphQL subscriptions
and pub/sub channels
·Server-side caching to make data available in
high speed in-memory caches for low latency
·JavaScript and TypeScript support to write
business logic
·Enterprise security with Private APIs to
restrict API access and integration with AWS WAF
·Built in authorization controls, with support
for API keys, IAM, Amazon Cognito, OpenID Connect providers, and Lambda
authorization for custom logic.
·Merged APIs to support federated use cases
There
few advanced servers they can help to expose DTO objects as graphql end
points. Hasura is one such grapqhql
implementation.
Hot Chocolate:Hot Chocolate is a GraphQL platform for that
can help you build a GraphQL layer over your existing and new infrastructure.
t is said that Express
GraphQL is the simplest way to run a GraphQL API server.
Express is a popular web application framework for Node.js allowing you to
create a GraphQL server with any HTTP web framework supporting connect styled
middleware including Express, Restify and, of course, Connect.
Getting started is as easy as installing some additional dependencies in form
of npm install express express-graphql graphql --save\
is an open-source GraphQL server compatible with any GraphQL
client and it's an easy way to build a production-ready, self-documenting
GraphQL API that can use data from any source. Apollo Server can be used as a
stand-alone GraphQL server, a plugin to your application's Node.js middleware,
or as a gateway for a federated data graph. Apollo GraphQL Server offers:
easy setup - client-side can start fetching data instantly,
incremental adoption - elastic approach to adding new features,
you can add them easily later on when you decide they're needed,
universality - compatibility with any data source, multiple build
tools and GraphQL clients,
production-ready - tested across various enterprise-grade
projects
Hot Chocolate
Hot Chocolate is a GraphQL server you can use to create GraphQL
endpoints, merge schemas, etc. Hot Chocolate is a part of a .NET based ChilliCream
GraphQL Platform that can help you build a GraphQL layer over
your existing and new infrastructure. It provides pre-built templates that let
you start in seconds, supporting both ASP.Net Core as well as ASP.Net Framework
out of the box.
API PLATFORM
API
Platform is a set of tools that combined build a modern
framework for building REST and GraphQL APIs including GraphQL Server. The
server solution is located in the API Platform Core Library which is built on
top of Symfony 4 (PHP) microframework and the Doctrine ORM. API Platform Core
Library is a highly flexible solution allowing you to build fully-featured
GraphQL API in minutes.
Here is good video to compare different Graphql
servers and bench marking among them.
Use
case 3: What are the challenges working with graphql . We can look at few
patterns which are popular in implementing Graphql.
Security:
Here
is few best practices for securing GraphQL end points. It is important to follow
best practices to over come cyber attacks which involve brute force attack , Malicious
Queries or batching multiple Queries.
Now that we've
covered the basics of GraphQL API security when it comes to the code, let's
shift our focus to essential best practices for securing your APIs that extend
beyond just what is implemented within the code itself. Here are nine best
practices to take into consideration when implementing GraphQL.
1. Conduct Regular Security Audits and
Penetration Testing Regularly
audit your GraphQL APIs and perform penetration tests to uncover and address
vulnerabilities before they can be exploited. Use automated scanning tools and
professional penetration testing services to simulate real-world attack
scenarios.
2. Implement Authentication and Authorization Use standard
authentication protocols like OAuth 2.0, OpenID Connect, or JWT-based auth.
Implement fine-grained authorization logic to ensure users and services can
only access the data they are permitted to see or manipulate.
3.
Encrypt Data in Transit and at Rest Always use TLS
(HTTPS) to encrypt data in transit. For data at rest, use robust encryption
algorithms and secure key management. This is crucial to protecting sensitive
data, such as user credentials, personal information, or financial records.
4. Effective Error Handling, Logging, and Input
Validation Ensure that
error messages do not expose internal details of your schema or implementation.
Maintain comprehensive logs for debugging and auditing but never log sensitive
data. Validate and sanitize all inputs to thwart injection-based attacks.
5. Use Throttling, Rate Limiting, and Query
Depth Limiting Limit the
number of requests per client or per IP address. Apply query depth and
complexity limits to prevent resource starvation attacks. An API gateway or
middleware solution can enforce these policies automatically.
6. Ensure Proper API Versioning and Deprecation
Strategies Adopt
transparent versioning practices to ensure users know when changes occur.
Provide a clear migration path and sunset deprecated versions responsibly,
giving users time to adapt.
7.
Embrace a Zero-Trust Network Model Assume no user
or system is trustworthy by default. Employ strict verification mechanisms at
every layer, enforce the principle of least privilege, and segment the network
for added security.
8. Automate Scanning and Testing for Vulnerabilities Integrate
vulnerability scanning into your CI/CD pipeline. Perform both static (SAST) and
dynamic (DAST) checks to catch issues before they reach production, adjusting
to new threats as they arise.
9.
Secure the Underlying Infrastructure Apply security
best practices to servers, containers, and cloud platforms. Regularly patch,
monitor for intrusions, and enforce strict firewall and network rules.
Infrastructure security often complements API-level security measures.
General recommendations
To ensure protection from a global point of view on a GraphQL API, several protections can be put in place.
By default, GraphQL implementations have default configurations that should be changed:
Disable introspection. This option is enabled by default in most implementations, but should be disabled unless it is considered necessary.
Disable GraphiQL. This is an implementation of GraphQL which is useful during the application development phase, but which should not be present in a production application unless it is considered necessary.
This is not necessarily possible on all implementations, or else implies implementing a ‘custom’ solution, but making the suggestions inaccessible to prevent an attacker from widening his scope of attack.
Preventing denial of service
GraphQL is particularly vulnerable to denial of service attacks if it is incorrectly configured. This type of attack impacts the availability and stability of the API, making it slower or even unavailable.
Here are a few recommendations that can be followed to protect against this type of attack:
Define a maximum depth for queries
Define a maximum limit on the amount of data that can be returned in a response
Apply a throughput limit to incoming requests, by IP, user or even both
Preventing batching attacks
As we saw earlier, batching attacks can be used to carry out bruteforce attacks. To defend against this type of attack, it is necessary to impose limits on incoming requests:
Impose a limit on the maximum number of objects in the same request
Limit the number of queries that can be executed at the same time
Prevent object batching on sensitive queries/mutations
One solution may be to create a concurrent request limit at code level on the number of objects a user can request. This way, if the limit is reached, the user’s other requests would be blocked, even if they were contained in the same HTTP request.
User input validation
The user input sent to the GraphQL API must be strictly validated. This input is often reused in multiple contexts, whether HTTP, SQL or other requests. If it is incorrectly validated, this could lead to injection vulnerabilities.
To validate user input, you can follow these recommendations:
Use GraphQL-specific types, such as scalars or enums. Add custom validators if you need to validate more complex data.
Use a whitelist of authorised characters according to the expected data
Reject invalid entries with non-verbose responses, so as to avoid revealing too much information about the operation of the API and its validation.
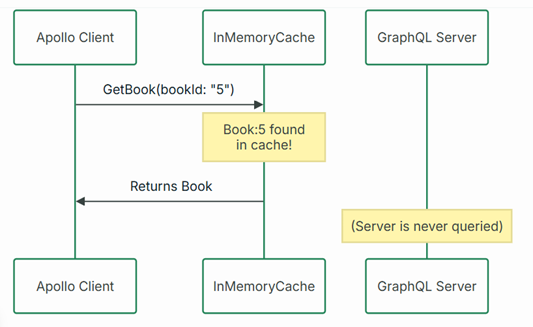
Caching:
Here is one example where
apollo client cache response of an object.
Best Design patterns:
Here is one way to look at Design patterns with graphQL. GraphQL with BFF is
mostly used pattern But still we can see some monolithics use graphql server to
deliver their controller end points and use new UI infrastructure . It depends
on application design and other factors which helps to decide using graphQL.
Here is simple example where Graphql can be used as aggregating
data from 3 services and also joining all data and service it as single out
put.
BookService:
allows to get books.
AuthorService:
allows to get books authors.
InventoryService:
allows to get books inventory.
BookComposerService:
is the API Composer Service that allows us to get a view, joining data
coming from the previous three services. This service is the only one that
will be exposed externally to the k8s cluster via a deployment that
includes a service defined as NodePort, instead all the other services
will be exposed only internally, so their pods will be exposed via k8s
services deployed as ClusteIP.
Complex Graphql Queries:
As shown below directive @export used to pass user name from first query result to second query and retrieving blog posts. It is one use case where one query depends on other and it is possible to achieve this using custom directives. Not all GraphQL servers support these kind of customizations but there are many such features in each GraphQL server and which are unique in optimizing query execution and achieving better result.