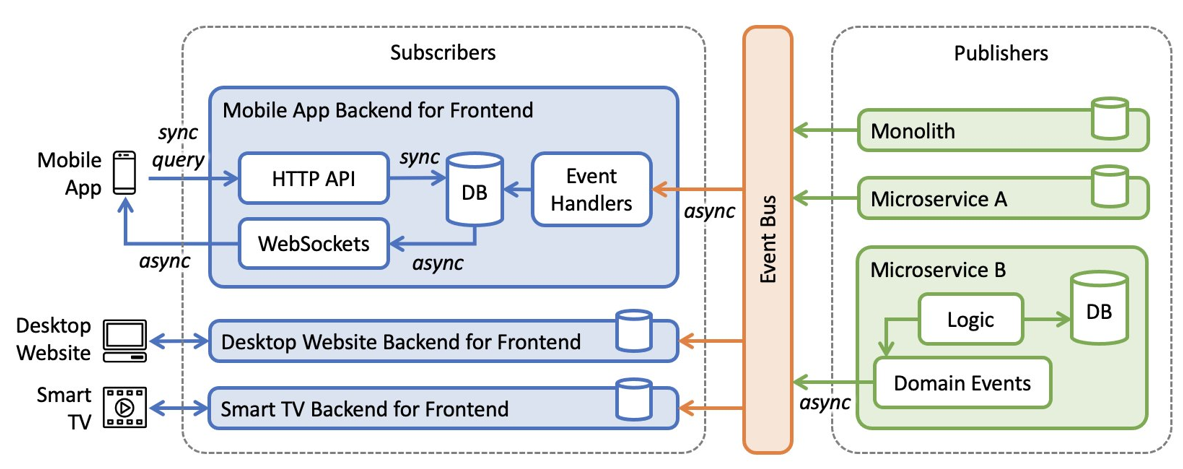
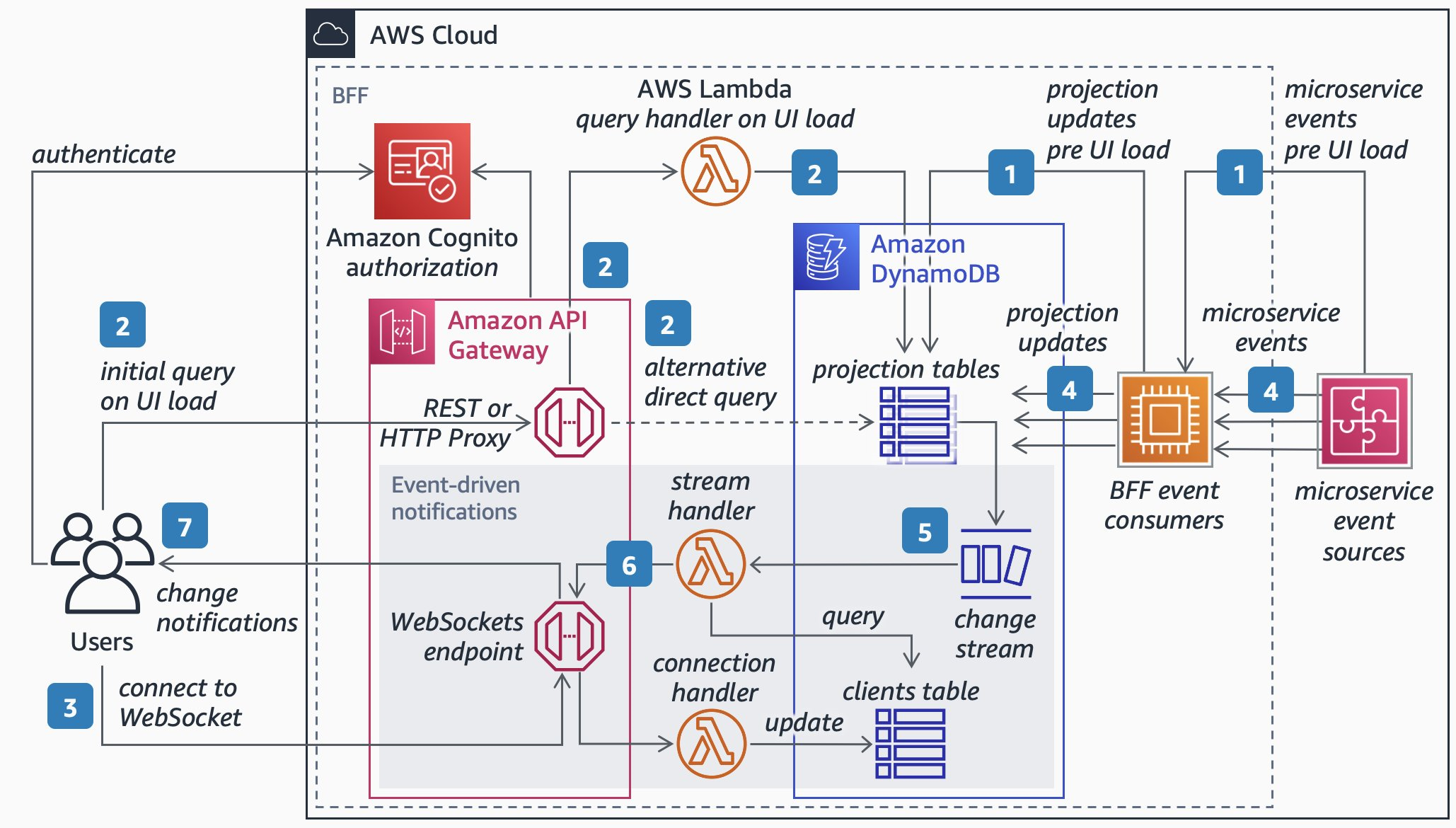
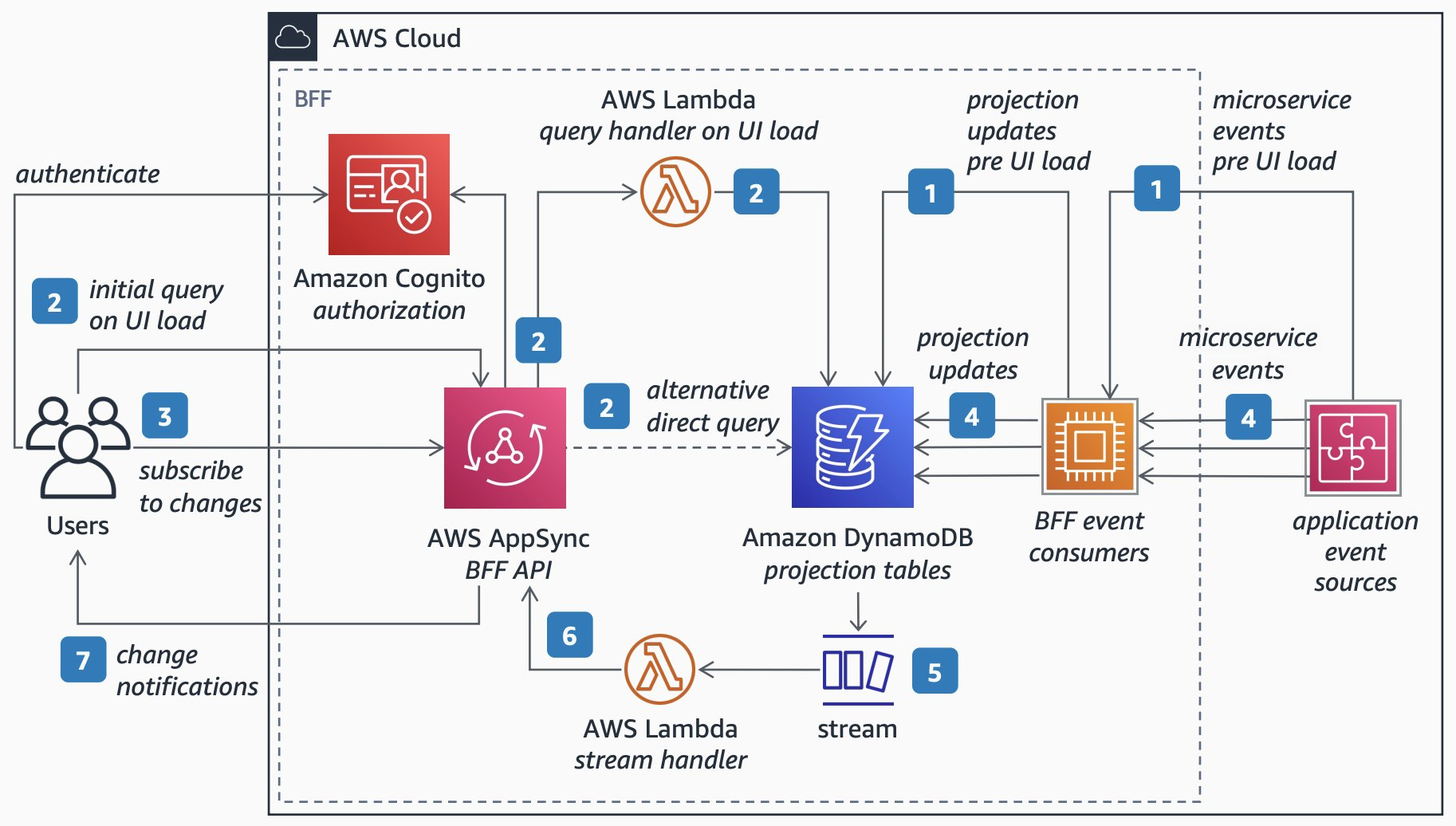
Part 1 BFF design article explains what are the main advantages of Graphql for implementing BFF and important scenarios where Graphql can be used. Other aspects like security and common anti design patterns and how to over come them. Articles don't discuss about in-depth explanation of how to design schema ,query , types and mutations .
Right now selecting a particular graphql server mostly depend on the programming language used for application development., there are few vendors having solution and can be adopted without much comparison of alternative deigns. The choice mostly linked to the programming language being used in application/ product. But this will change as BFF is very much part of best design patterns now like api layer design or repository pattern , slowly BFF layer become part of most of new design / architecture diagrams . which indicates that better tooling and handling complex scenarios needs better choice interms of tooling along with choice of Graphql server. So the article will explain total end to end system design not just setting up Graphql server. Newly developed solution for graphql server like Yogagraphql already has more than 40k downloads. It shows that there will be more design alternatives going forward.
If we look at some of the security risks discussed in Book "Black Hat GraphQL" it also give examples how graphql servers by few vendors providing additional security. So there are many parameters along with setting up graphql server. Security, schema generation, managing sub graph - and moving towards federation graphql . All these parameters helps to design better grapql eco system. I am using apollo client which can cache client side data if the query is not changed. These are few features by these vendors some times can influence whole design.

Part 2 in this article we can look at the available design options and the suitable use case will be discussed. It is important to understand in depth capabilities of the existing frameworks which can help to quickly bring Graphql server and Graphql client and can also add lot of features like security , build , logging , scalability and other components as plug and play , as these frameworks are designed with lot of add on components and easy to integrate using API .
Design Objectives
Let us consider few important use cases where Graphql being used extensively. One of the design discussion is about all the objects in graphql are connected like graph and also query represents closely with the data design.
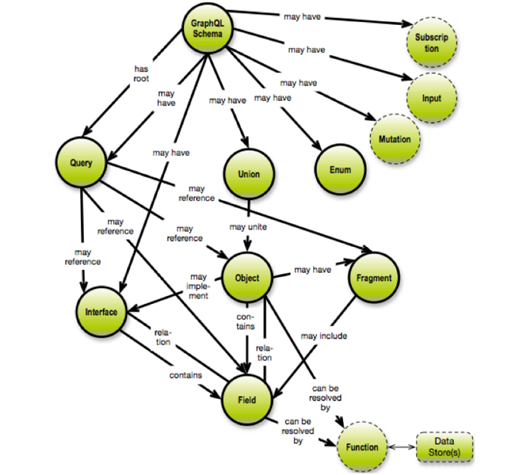
There are many articles discussing above inherent feature of Graphql and advantages and disadvantages. As one article explains it as schema is graph and queries results in tree only. The articles also extending advantage of using graphql for graph based data bases. It also explains with good examples and how to validate and maintain data quality so that it works with graphql better way.
One way to look at designing Graphql server with Neo4j or similar frameworks are more close to data driven design . There could be many variations to above.
There few advanced graphql servers they can help to expose DTO objects as graphql end points. Hasura is one such grapqhql implementation. Similar thinking and design but Hasura will talk more about DTO object instead of data base type.
Let us look at AWS design for Graphql server with the APP Sync based design.

As explained by AWS the three subgraphs are composed into the Fusion gateway which is ran as a Fargate service behind an Application Load Balancer.
Above system developed by aws brings in the following advantages as it was shipping graphql server with lot of features already available and which can be extended based on application design. Here are few advantages of using above
Real-time data synchronization using subscriptions. Integration with AWS services like DynamoDB, Lambda, and S3.Simplified authorization with Amazon Cognito, API keys, and IAM.
Api load balancing and security capability of IAM and also can make use of AWS components quickly. Dev focus could be implementing schema , types and query files. This kind of design approach where lot of components can be plugged in can reduce development time . we can discuss more about some of the major features which can be more attractive in selecting the design when we try to compare different designs available for a real time example.
Hot Chocolate: Hot Chocolate is a GraphQL
platform for that can help you build a GraphQL layer over your existing and new
infrastructure.
More precisely Hot Chocolate is an open-source GraphQL server for the Microsoft .NET platform that is compliant with the newest GraphQL October 2021 spec + Drafts, which makes Hot Chocolate compatible to all GraphQL compliant clients like Strawberry Shake, Relay, Apollo Client, and various other GraphQL clients and tools. As it is more Microsoft platform based design and can work closely with Microsoft infrastructure.
Express Graph ql, Appollo Graphql server and server other popular frameworks available to implement grpahql server. We can dive deep when we try to design couple of real time example after discussing some more important design patterns and frameworks.
Design Patterns and Use cases
Let us consider scenario where an monolithic application having MVC pattern which was adopted by many legacy systems. When it is required to redesign above systems based on latest micro service based cloud enabled applications , new patterns like BFF, serverless and other technologies are recommended for new application design.
Use case 1: Refracting legacy Application:
In a simple design if all controller end points are mapped to an graphql end point and Client which is view decoupled form MVC pattern it is one way to break monolithic application. This one is most adopted approach in industry I can see this approach is best use case in industry for introducing BFF layer and graphql.
Let us look at complete set of components and process involved in adopting Graphql
Design Graphql Server which also involve designing schema, query, types and resolvers to fetch data.
Designing some cache components and optimizing data fetching using pagination and error handling, Client side design to interact with grapqhql server.
Next will be API management related aspects like versioning and load balancing.
Tooling : Here comes the major design decision as lot of vendors gives readily available schema generators, Visual designers for schemas ,query and types design, testing frameworks and every thing required to set up Graphql server and to perform above 4 step with attractive low code no code kind of approach. So all pending work could be just hooking resolvers with data end points.
The above refactoring and redesign exercise can be extended to address lot of design considerations like separation of concerns or abstracting data
We can discuss in depth scenarios for above design transition form MVC to Graphql server and then we can consider different platforms available which can be best fit for the above refracturing or tech refresh exercise.
Use case 2 API Aggregation : Aggregating multiple apis internal and./or external and abstracting api details from Clients.
Use case 3 BFF Design: Building more modular patterns in application design using BFF.
User case 4 Using Graphql along with Micro srvices : Graph QL for managing microservices and service mesh.
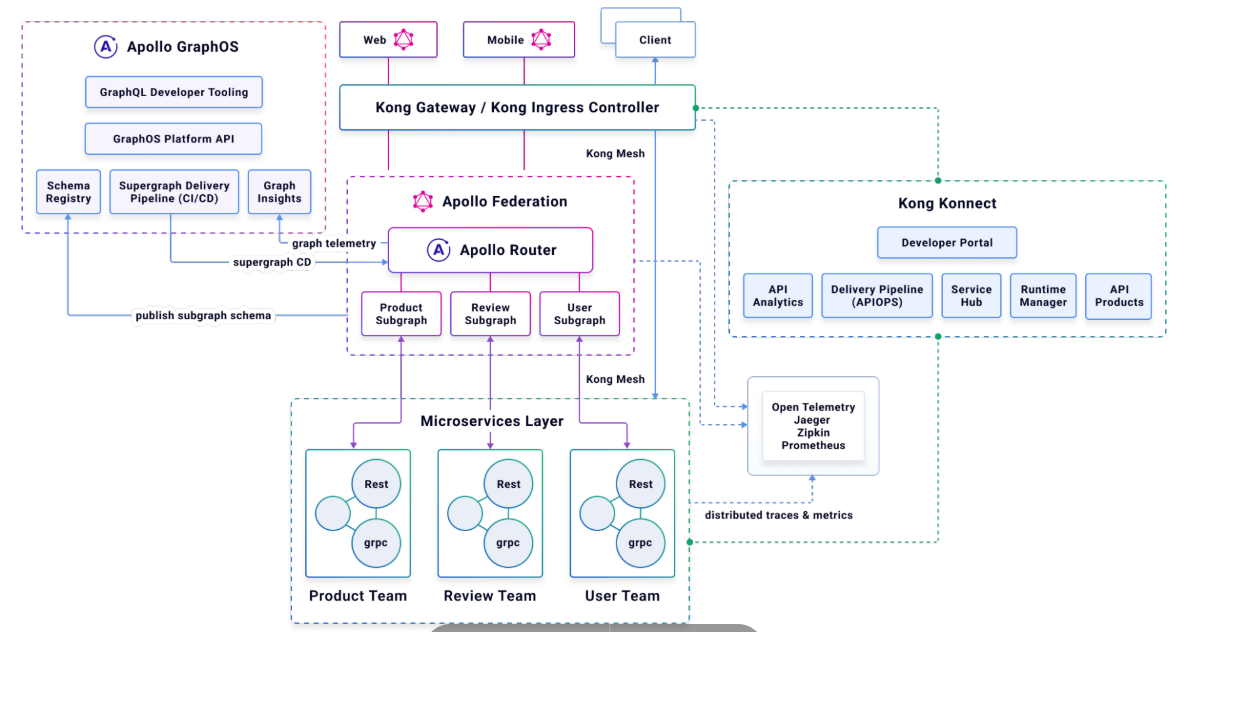
Here is one example of robust architecture for use case 4 using applo federation and microservices with an Api gateway
Ref: https://talashlogs.blob.core.windows.net/talash-drive/leveraging-graphql-for-next-generation-api-platforms.pdf
Important design aspects for this reference architecture are :
Appollo provides lot of ready to use components along with Graphql server. As discussed above it is like a platform which can give lot of other components to maintain Graphql infrastructure and quickly build application. As shown in this diagram Apollo provides a GraphQL developer platform (GraphOS), which includes developer tooling, a schema registry, and a supergraph CI/CD pipeline and high-performance supergraph runtime.
Even Appollo clients provided can manage cache control at client side . Cache management is bit tricky and needs more components to maintain server cache and client cache which we can discuss later.
Other components in diagram are Kong API gateway . This could be any other API manager . Important point here is Micro services needs service mesh to communicate and then they are connected to Graphql server. Bit of load balancing and security achieved with these API gateways embedded in the design.
Security is often handled with a defense-in-depth or zero-trust approach, where each layer of the stack provides security controls for authentication, authorization, and blocking
malicious requests. Client-side traffic shaping with rate limits, timeouts, and compression can be implemented in the API gateway or supergraph layer, and subgraph traffic shaping
(including deduplication) can be implemented at the supergraph layer. Observability via Open Telemetry is supported across the stack to provide complete end-to-end visibility into each
request via distributed tracing along with metrics and logs.
(Apollo Router).
Here is another way to classify above use cases.-
Pattern
Advantages
Challenges
Best Use Cases
Client-Based GraphQL
Easy to implement, cost-effective
Performance bottlenecks, limited scalability
Prototyping, small-scale applications
GraphQL with BFF
Optimized for clients, better performance
Increased effort, higher complexity
Applications with diverse client needs
Monolithic GraphQL
Centralized management, consistent API
Single point of failure, scaling issues
Medium-sized applications, unified schema
GraphQL Federation
Scalable, modular, team autonomy
Increased complexity, higher learning curve
Large-scale, distributed systems
Best practices
What are the key principles of schema design in GraphQL?
- Unified Schema: A GraphQL schema defines a collection of types and their relationships in a unified manner. This allows client developers to request specific subsets of data with optimized queries, enhancing flexibility.
- Implementation-Agnostic: The schema is not responsible for defining data sources or storage methods, making it adaptable to various backend implementations without requiring changes to the schema itself.
- Field Nullability: By default, fields can return null, but non-nullable fields can be specified using an exclamation mark (!). This provides control over data integrity and error handling, contributing to robust and scalable schema design.
- Query-Driven Design: The schema should be designed based on client needs rather than backend data structures. This approach ensures that the schema evolves with client requirements, supporting flexibility and scalability.
- Version Control and Change Management: Maintaining the schema in version control allows tracking of changes over time. Most additive changes are backward compatible, but careful management of breaking changes is essential for scalability.
- Use of Descriptions: Incorporating Markdown-enabled documentation strings (descriptions) in the schema helps developers understand and use the schema effectively, promoting a flexible development environment.
- Naming Conventions: Consistent naming conventions, such as camelCase for fields and PascalCase for types, ensure clarity and ease of use across different client implementations, aiding in scalability
Tools and devops
References:
Apollo graphql federation:
https://talashlogs.blob.core.windows.net/talash-drive/Apollo-graphql-at-enterprise-scale-final.pdf
Security and pen test
https://talashlogs.blob.core.windows.net/talash-drive/Black+Hat+GraphQL_bibis.ir.pdf
PentestingEverything/API Pentesting/GraphQL at main · m14r41/PentestingEverything
Design patterns
Naming and best practices and schema design
GraphQL: Standards and Best Practices | by Andrii Andriiets | Medium
GraphQL Best Practices for Efficient APIs