The solution proposed combines two patterns: 1) the Backends for Frontends (BFF) pattern, where applications have one backend per user experience, instead of having only one general-purpose API backend; and 2) the Publisher–Subscriber (pub/sub) pattern, where microservices announce events to multiple interested consumers asynchronously, without coupling the senders to the receivers. When combined, these two patterns allow frontend clients to load UI-ready data projections and to refresh the UI with event-driven notifications, resulting in a high-performant near-real-time experience for end-users.
To explain the solution to both REST and GraphQL API developers, we provide two similar architecture diagrams addressing each API technology.
The BFF pattern
According to Sam Newman, the Backend For Frontend (BFF) pattern refers to having one backend per user experience, instead of having only one general-purpose API backend.
Traditionally, the approach to accommodating more than one type of UI is to provide a single, server-side API, and add more functionality as required over time to support new types of mobile interaction. The following challenges may result from this approach:
- Mobile devices make fewer calls, and want to display different (and probably less) data than their desktop counterparts – this means that API backends need additional functionality to support mobile interfaces.
- Modern application UIs are increasingly adopting reactive strategies to provide real-time feedback to end-users (for example via WebSockets), and different devices may implement different technology stacks to support it.
- API backends are, by definition, providing functionality to multiple, user-facing applications – this means that the single API backend can become a bottleneck when rolling out new delivery, due to the many changes being made to the same deployable artifact.
To address these challenges, Sam suggests that you should think of the user-facing application as being two components: a client-side application living outside your perimeter, and a server-side component (the BFF) inside your perimeter. According to him, the BFF is tightly coupled to a specific user experience, and will typically be maintained by the same team as the user interface, thereby making it easier to define and adapt the API as the UI requires, while also simplifying the process of lining up releases of both the client and server components.
Following Sam’s suggestion, the BFF pattern has been adopted by companies like Netflix, where their Android team seamlessly swapped the API backend of the Netflix Android app, enabling them to work with their endpoint with increased level of scrutiny, observability, and integration with Netflix’s microservice ecosystem.
Components of an event-driven BFF on AWS
Assuming that you already have an event-driven architecture in place, regardless of having events generated by multiple microservices or by a single monolith, then you already have enough to start building your decoupled event-driven Backends-for-Frontends (BFFs) for each of your end-user experiences.
The diagram below presents a high-level view of the architecture and its message flow. Representing the domain publishers on the right, each with its own domain-specific aggregate database; and the BFF subscribers on the left, each with its own user-experience-specific projection database. In the middle, there’s an event bus propagating domain state changes, allowing publishers and subscribers to remain decoupled.
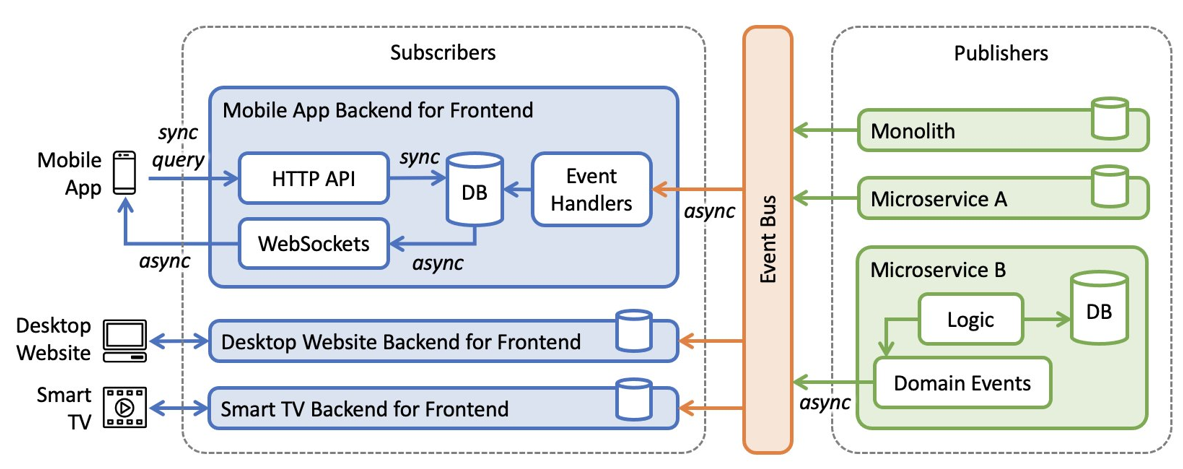
Figure 1. Message flow diagram.
The event-driven BFF solutions described in this blog post rely on a technology-specific API, in addition to the following common components:
- A NoSQL database to store domain projection tables, which also supports Change Data Capture (CDC). Here, we use Amazon DynamoDB – a fast, flexible NoSQL database service for single-digit millisecond performance at any scale.
- A compute-layer to process requests and to integrate the CDC stream with the API. Here, we use AWS Lambda – a serverless, event-driven compute service that lets you run code without thinking about servers or clusters.
- An authentication and authorization mechanism to protect the API. Here, we use Amazon Cognito – a simple and secure service for user sign-up, sign-in, and access control.
Building an event-driven REST BFF using API Gateway
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. APIs act as the “front door” for applications to access data, business logic, or functionality from your backend services. Using API Gateway, you can create RESTful APIs and WebSocket APIs that enable real-time two-way communication applications.
The following architecture diagram describes, using Domain-Driven Design (DDD) concepts, how to leverage API Gateway WebSocket APIs to create an event-driven UI for end-users. For a PDF version of this diagram, see this link.
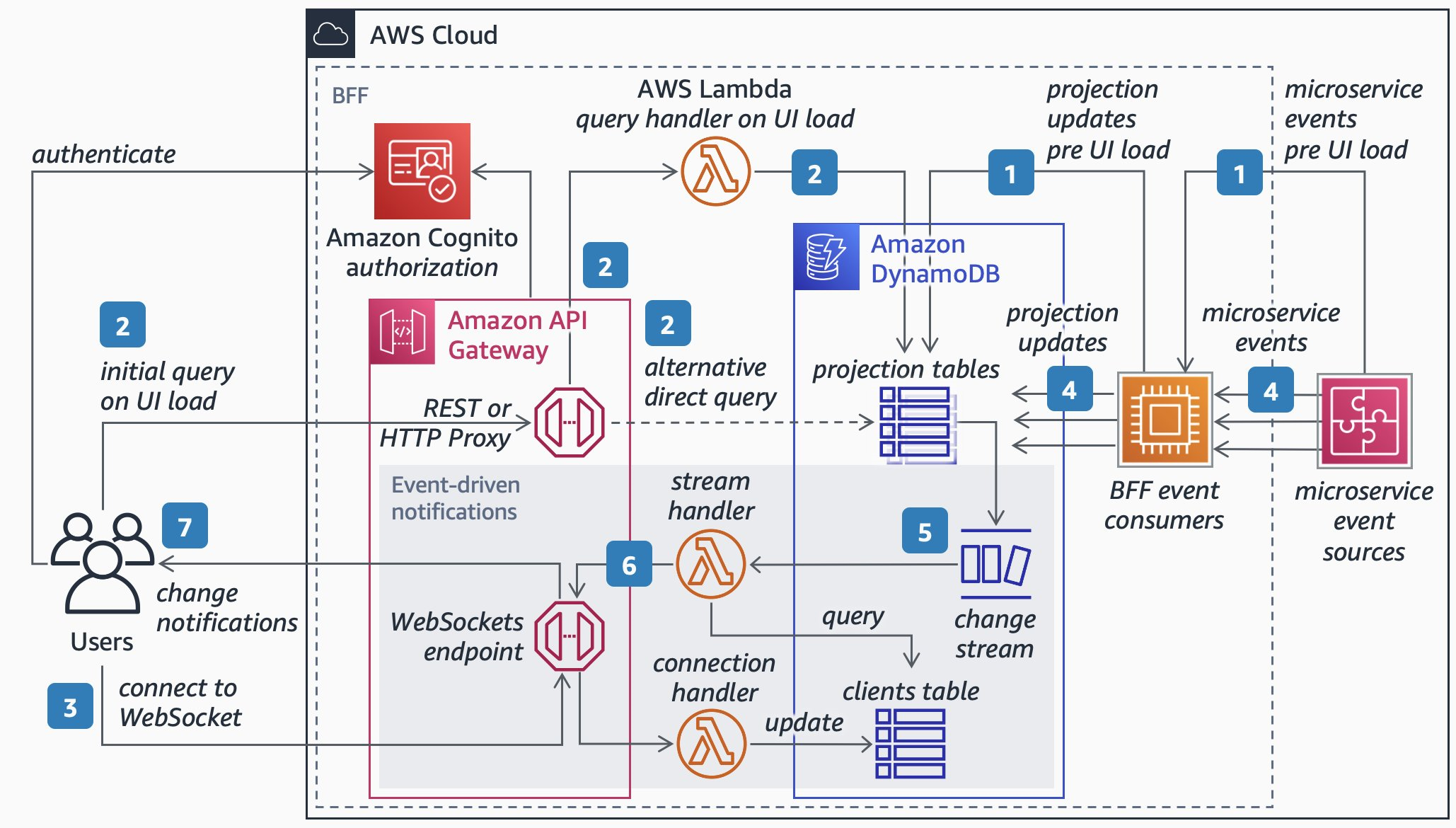
Figure 2. Diagram of RESTful BFF using API Gateway.
Implementation steps:
- Catch the events from your application with purpose-built BFF event consumers. These are responsible for updating denormalized data projections in Amazon DynamoDB for frontend consumption.
- On UI load, frontend clients authenticate with Amazon Cognito, then query the data by invoking the BFF API built with Amazon API Gateway. The data is then fetched in DynamoDB, either directly by API Gateway or via a BFF query handler built with AWS Lambda.
- Frontend clients subscribe for any subsequent data changes by connecting to a BFF WebSocket endpoint provided by API Gateway, which triggers the update of the “connected clients” table.
- Continue to consume and process all relevant events from your application using the BFF event consumers. These consumers continuously update the denormalized frontend data view in the BFF database in real time.
- Subscribe to all events resulting from data changes in the BFF database using Amazon DynamoDB Streams, then register a trigger in AWS Lambda to asynchronously invoke a BFF stream-handler Lambda function when it detects new stream records.
- Your BFF stream handler then pushes notifications to clients connected to API Gateway’s WebSockets.
- When the change notification from API Gateway is received by the frontend clients, they can refresh the UI content.
Building an event-driven GraphQL BFF using AppSync
We see organizations increasingly choosing to build APIs with GraphQL because it helps them develop applications faster, by giving frontend developers the ability to query multiple databases, microservices, and APIs with a single GraphQL endpoint.
AWS AppSync is a fully managed service that makes it easy to develop GraphQL APIs by handling the heavy lifting of securely connecting to data sources like Amazon DynamoDB, AWS Lambda, and more. Once deployed, AWS AppSync automatically scales your GraphQL API execution engine up and down to meet API request volumes. Additionally, AppSync adds caches to improve performance, supports client-side data stores that keep off-line clients in sync, and supports real-time updates via transparent subscriptions over WebSockets.
The following architecture diagram describes, using Domain-Driven Design (DDD) concepts, how to leverage AppSync subscriptions to create an event-driven UI for end-users. For a PDF version of this diagram, see this link.
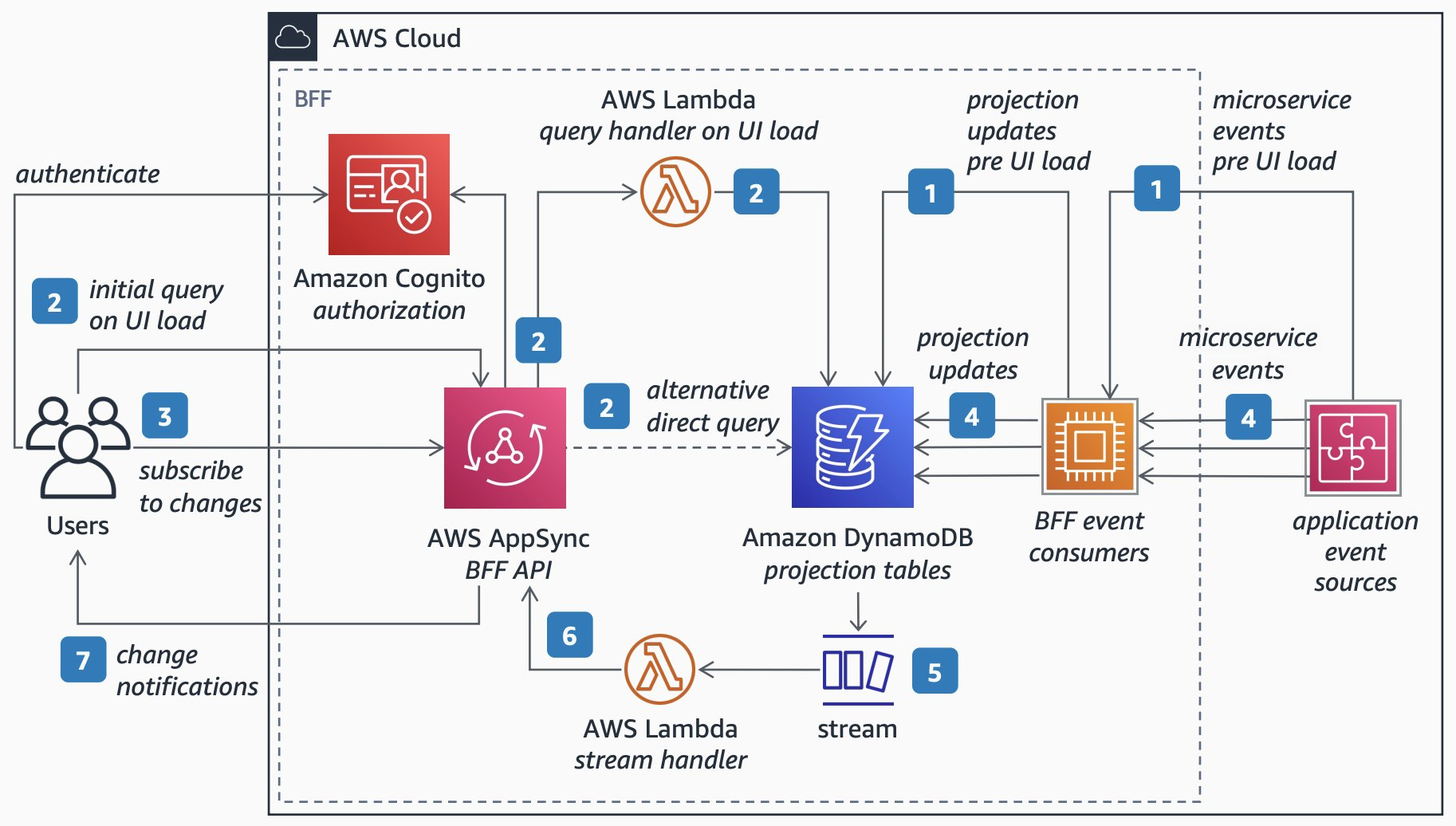
Figure 3. Diagram of GraphQL BFF using AppSync.
Implementation steps:
- Catch the events from your application with purpose-built BFF event consumers. These are responsible for keeping a denormalized view of data in Amazon DynamoDB for frontend consumption.
- On UI load, frontend clients authenticate with Amazon Cognito, then query the data with GraphQL by invoking the BFF API built with AWS AppSync. The data is then fetched in DynamoDB, either directly by AWS AppSync or via a BFF query handler built with AWS Lambda.
- Frontend clients subscribe for any subsequent data changes using AWS AppSync subscriptions over WebSockets.
- Continue to consume and process all relevant events from your application using the BFF event consumers. These consumers continuously update the denormalized frontend data view in the BFF database in real-time.
- Subscribe to all events resulting from data changes in the BFF database using Amazon DynamoDB Streams, then register a trigger in AWS Lambda to asynchronously invoke a BFF stream-handler Lambda function when it detects new stream records.
- Your BFF stream handler then invokes an empty mutation on the AWS AppSync GraphQL schema, purposely created to force the subscription to be triggered, thus sending a notification to clients.
- When the change notification from AWS AppSync is received by the frontend clients, they can refresh the UI content.
AWS AppSync provides a simplified WebSockets experience with real-time data, connections, scalability, fan-out and broadcasting which are all handled by the AWS AppSync service, allowing developers to focus on the application use cases and requirements instead of dealing with the complexity of infrastructure required to manage WebSockets connections at scale.
The AWS Lambda stream handler function in step 6 is triggered by new items being inserted into the Amazon DynamoDB table. It reads these items and updates AWS AppSync, alerting it to the new data. A sample of this code, written in node.js, is available here on GitHub as part of an AWS Sample for deploying AWS AppSync in a multi region setup. The primary functions were extracted and are explained below.
The code below shows the entry point to the Lambda function. It receives an event from DynamoDB, triggered by new data in the stream. For each new entry, if it is data that has been inserted (rather than updated or deleted), it will parse the data and call the executeMutation function.
The code below is the executeMutation function that mutates AWS AppSync with the new data received from the DynamoDB stream. Using the third-party library Axios (a promise-based HTTP client for node.js) it connects to the AppSync API endpoint and posts the mutation.
The mutation is generated using the following GQL code:
Conclusion
The BFF pattern refers to having one backend per user experience, instead of having only one general-purpose API backend.
By implementing the BFF pattern in an event-drive architecture, you can improve end-user customer experience on your UI by providing near-real-time visual updates when your microservices raise events about mutations in domain aggregates.
In this blog post, we explained how developers can apply the BFF pattern to their REST and GraphQL APIs to load UI-ready data projections and refresh the UI with event-driven notifications.
You can download the detailed reference architectures in PDF for Amazon API Gateway here and AWS AppSync here.




