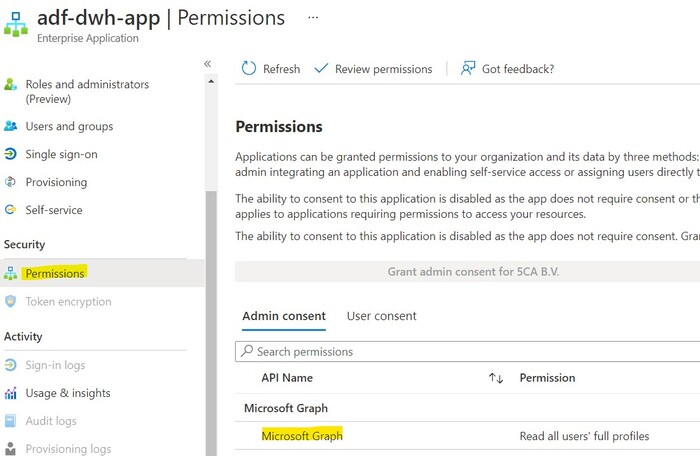
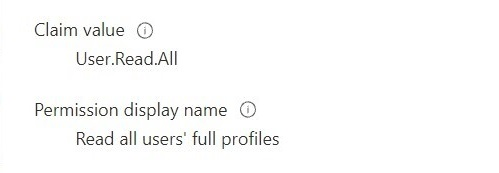
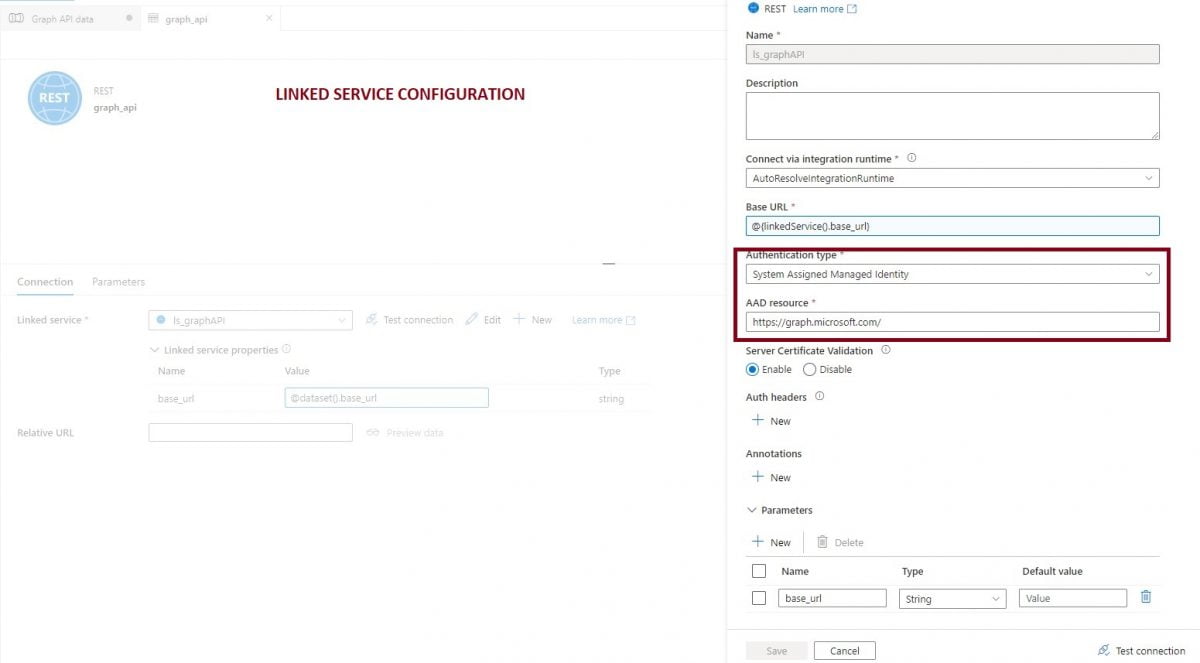
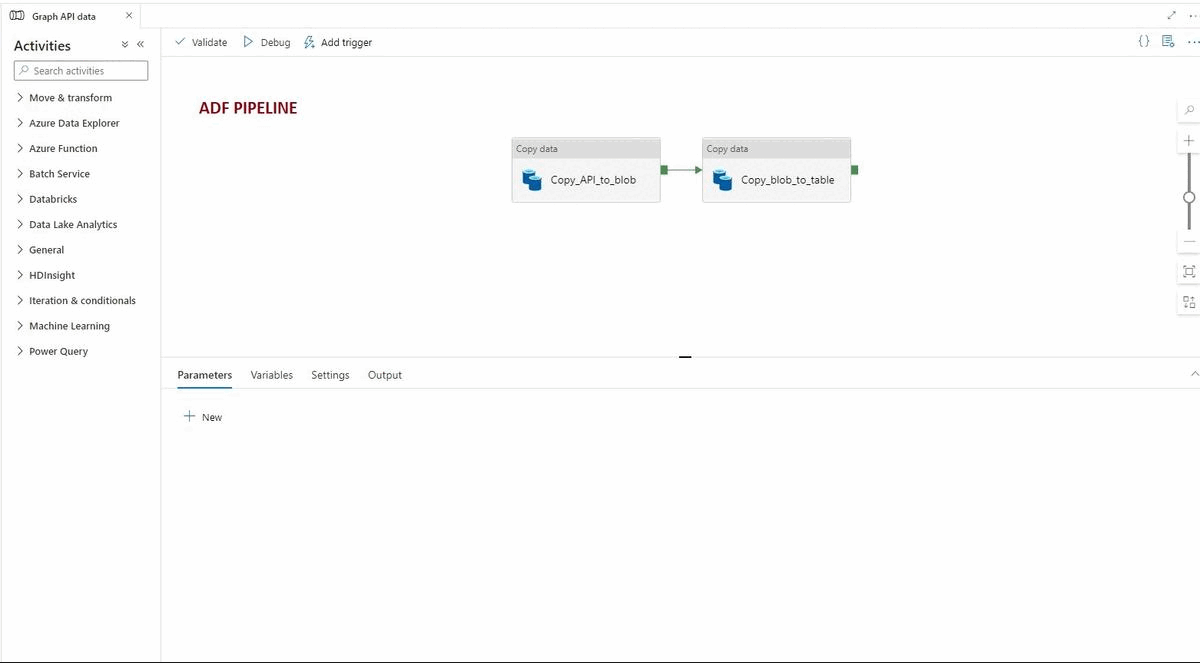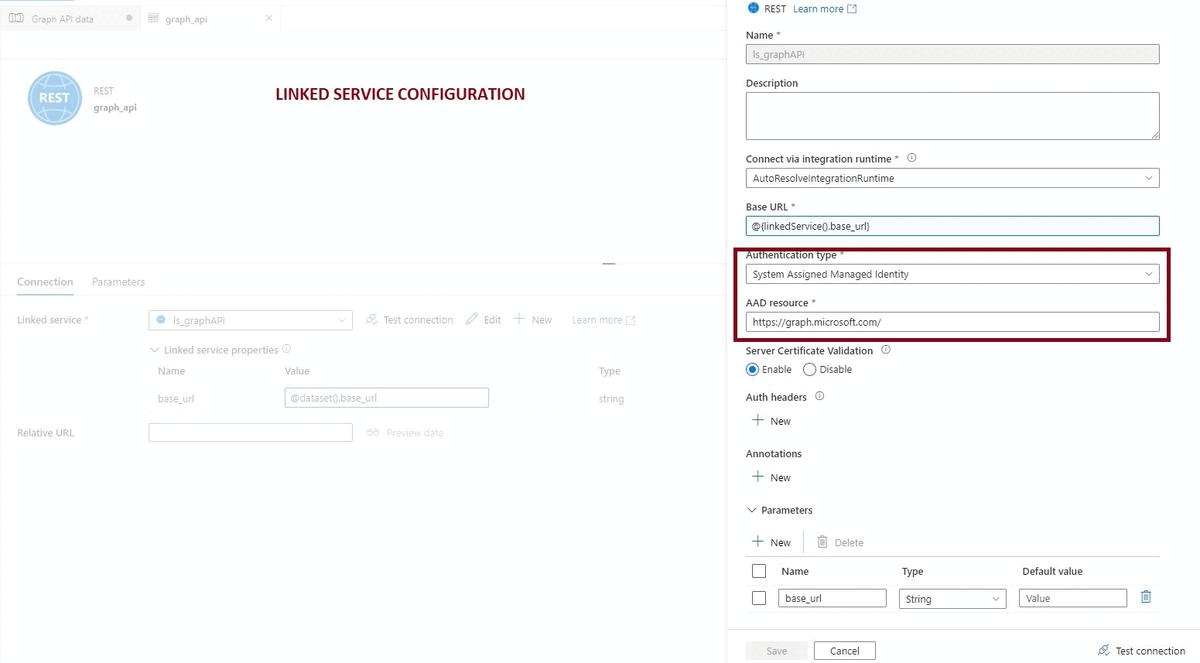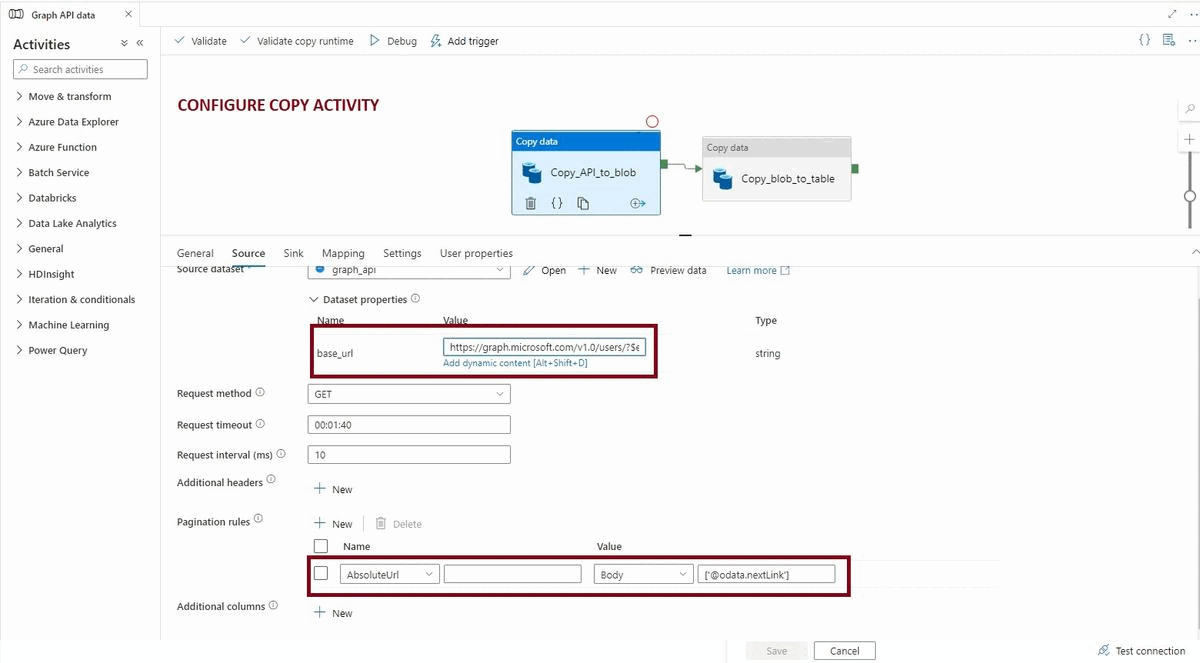
Recently I've been tasked with building a PoC of Azure Functions based GraphQL service. I like tasks like this, especially if I can share my experience. I hope someone will benefit from this one.
Probably the most popular implementation of GraphQL for .NET is graphql-dotnet. It doesn't have a ready to use integration with Azure Functions, but it has a ready to use integration with ASP.NET Core. Taking into consideration that Azure Functions are built on top of ASP.NET Core and recently have been given support for dependency injection, that's the next best thing.
Building a GraphQL Azure Function
The core part of graphql-dotnet server implementation is available as a separated package: GraphQL.Server.Core. This is great. It gives us all the needed services without the strictly ASP.NET Core specific stuff (like middleware). This means that GraphQL set up for Azure Functions can be done in the same way as for ASP.NET Core (by registering dependency resolver, schema, services, and types).
[assembly: FunctionsStartup(typeof(Demo.Azure.Functions.GraphQL.Startup))]
namespace Demo.Azure.Functions.GraphQL
{
public class Startup : FunctionsStartup
{
public override void Configure(IFunctionsHostBuilder builder)
{
builder.Services.AddScoped<IDependencyResolver>(serviceProvider => new FuncDependencyResolver(serviceProvider.GetRequiredService));
builder.Services.AddScoped<StarWarsSchema>();
builder.Services.AddGraphQL(options =>
{
options.ExposeExceptions = true;
})
.AddGraphTypes(ServiceLifetime.Scoped);
}
}
}
This makes the IGraphQLExecuter service available to us. This is the heart of GraphQL.Server.Core. If we provide an operation name, query, and variables to the ExecuteAsync method of this service, it will take care of all the processing. So, we can inject that service and build our function based on it.
public class GraphQLFunction
{
private readonly IGraphQLExecuter<StarWarsSchema> _graphQLExecuter;
public GraphQLFunction(IGraphQLExecuter<StarWarsSchema> graphQLExecuter)
{
_graphQLExecuter = graphQLExecuter ?? throw new ArgumentNullException(nameof(graphQLExecuter));
}
[FunctionName("graphql")]
public async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = null)] HttpRequest req,
ILogger logger)
{
...
ExecutionResult executionResult = await _graphQLExecuter.ExecuteAsync(
operationName,
query,
variables?.ToInputs(),
null,
req.HttpContext.RequestAborted
);
...
}
}
Now we are faced with two challenges. One is getting operation name, query, and variables out of request. The other is writing ExecutionResult to the response.
The challenging part of getting operation name, query, and variables out of request is that, depending on request method and content type, there are four different ways to do that. Putting all that code into the function would be unnecessary noise. This is why I've decided to extract that code into an extension method. This allows the function to be very clean.
public class GraphQLFunction
{
...
[FunctionName("graphql")]
public async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = null)] HttpRequest req,
ILogger logger)
{
ExecutionResult executionResult = await _graphQLExecuter.ExecuteAsync(request);
...
}
}
I'm not putting the code of the extension method here, as there is nothing really special about it. You can find it on GitHub.
When it comes to writing ExecutionResult to the response, graphql-dotnet gives us IDocumentWriter service. We could use this service in our function to write directly to the response and then return something weird like null or EmptyResult, but again this would be quite ugly. It's better to write dedicated ActionResult. There is no problem with accessing services from ActionResult, so entire logic can be nicely encapsulated.
internal class GraphQLExecutionResult : ActionResult
{
private const string CONTENT_TYPE = "application/json";
private readonly ExecutionResult _executionResult;
public GraphQLExecutionResult(ExecutionResult executionResult)
{
_executionResult = executionResult ?? throw new ArgumentNullException(nameof(executionResult));
}
public override Task ExecuteResultAsync(ActionContext context)
{
if (context == null)
{
throw new ArgumentNullException(nameof(context));
}
IDocumentWriter documentWriter = context.HttpContext.RequestServices.GetRequiredService<IDocumentWriter>();
HttpResponse response = context.HttpContext.Response;
response.ContentType = CONTENT_TYPE;
response.StatusCode = StatusCodes.Status200OK;
return documentWriter.WriteAsync(response.Body, _executionResult);
}
}
In result, the function is only a couple lines long (even with some basic errors logging).
public class GraphQLFunction
{
...
[FunctionName("graphql")]
public async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Anonymous, "get", "post", Route = null)] HttpRequest req,
ILogger logger)
{
ExecutionResult executionResult = await _graphQLExecuter.ExecuteAsync(request);
if (executionResult.Errors != null)
{
logger.LogError("GraphQL execution error(s): {Errors}", executionResult.Errors);
}
return new GraphQLExecutionResult(executionResult);
}
}
Nice, let's see if it works. In my case, it didn't...
After preparing a request in Postman and sending it, as a response I received following error.
GraphQL.ExecutionError: Object reference not set to an instance of an object. ---> System.NullReferenceException: Object reference not set to an instance of an object.
at GraphQL.DocumentExecuter.ExecuteAsync(ExecutionOptions options)
Well, this doesn't say much. I've spent some time going through DocumentExecuter code and concluded that the most likely cause of NullReferenceException is one if it's constructor dependencies being null. The DocumentExecuter has two constructors. One allows for providing dependencies and the other uses defaults. The AddGraphQL registers DocumentExecuter, but none of its dependencies. It would suggest that it expects that the parameterless constructor will be used, but it's not what is happening. As AddGraphQL uses TryAddSingleton to register DocumentExecuter, it should be enough to register it earlier and enforce the correct constructor.
[assembly: FunctionsStartup(typeof(Demo.Azure.Functions.GraphQL.Startup))]
namespace Demo.Azure.Functions.GraphQL
{
public class Startup : FunctionsStartup
{
public override void Configure(IFunctionsHostBuilder builder)
{
...
builder.Services.AddSingleton<IDocumentExecuter>(new DocumentExecuter());
builder.Services.AddGraphQL(options =>
{
options.ExposeExceptions = true;
})
.AddGraphTypes(ServiceLifetime.Scoped);
}
}
}
Another attempt at sending a request and I saw the desired response. It works!
Adding Cosmos DB to the Mix
A database which goes well with Azure Functions is Azure Cosmos DB. It would be nice if we could use it in our GraphQL service. After all, it should only be a matter of registering DocumentClient as a service. It would also be nice if we could reuse the Azure Cosmos DB bindings configuration. I ended up with the below method.
public class Startup : FunctionsStartup
{
public override void Configure(IFunctionsHostBuilder builder)
{
builder.Services.AddSingleton<IDocumentClient>(serviceProvider => {
DbConnectionStringBuilder cosmosDBConnectionStringBuilder = new DbConnectionStringBuilder
{
ConnectionString = serviceProvider.GetRequiredService<IConfiguration>()["CosmosDBConnection"]
};
if (cosmosDBConnectionStringBuilder.TryGetValue("AccountKey", out object accountKey)
&& cosmosDBConnectionStringBuilder.TryGetValue("AccountEndpoint", out object accountEndpoint))
{
return new DocumentClient(new Uri(accountEndpoint.ToString()), accountKey.ToString());
}
return null;
});
...
}
}
It grabs the setting with connection string from IConfiguration, uses DbConnectionStringBuilder to get the needed attributes, and creates a new instance of DocumentClient. Now DocumentClient can be injected into query class and used to fetch the data.
internal class PlanetQuery: ObjectGraphType
{
...
public PlanetQuery(IDocumentClient documentClient)
{
Field<ListGraphType<PlanetType>>(
"planets",
resolve: context => documentClient.CreateDocumentQuery<Planet>(_planetsCollectionUri, _feedOptions)
);
}
}
What Else?
As part of my PoC I've also experimented with a data loader, as it's crucial for GraphQL performance. I didn't play with more complex queries and mutations, but it doesn't seem like there should be any issue. You can find the complete demo here.