Interseting point is : Space cloud basically helping to quickly adopt graphql a kind of hosted solution can be useful to validate this technology quickly..Implementing GraphQL from scratch can be overwhelming at first, especially if you aren’t used to it. But you also don’t want to miss on the amazing benefits that GraphQL has to offer. That’s why we have made Space Cloud - An open source GraphQL layer.
Monday, April 3, 2023
Sunday, April 2, 2023
Top 10 must-know Kubernetes design patterns
Interesting points: Explains how each pattern
focus on key important aspects like Health monitoring and reproting,
distribution of load or even dynamic load balancing depending on the
load.

Patterns
Here are the must-know top 10 design
patterns for beginners synthesized from the
Kubernetes Patterns book. Getting familiar with these patterns will
help you understand foundational Kubernetes concepts, which in turn will help
you in discussions and when designing Kubernetes-based applications.
There are many important concepts in
Kubernetes, but these are the most important ones to start with:
To help you understand, the patterns
are organized into a few categories below, inspired by the Gang of Four's design
patterns.
These patterns represent the
principles and best practices that containerized applications must comply with
in order to become good cloud-native citizens. Regardless of the application's
nature, you should aim to follow these guidelines. Adhering to these principles
will help ensure that your applications are suitable for automation on
Kubernetes.
Health Probe dictates that every container
should implement specific APIs to help the platform observe and manage the
application in the healthiest way possible. To be fully automatable, a
cloud-native application must be highly observable by allowing its state to be
inferred so that Kubernetes can detect whether the application is up and ready
to serve requests. These observations influence the life-cycle management of
Pods and the way traffic is routed to the application.
Predictable Demands explains why every container
should declare its resource profile and stay confined to the indicated resource
requirements. The foundation of successful application deployment, management,
and coexistence on a shared cloud environment is dependent on identifying and
declaring the application's resource requirements and runtime dependencies.
This pattern describes how you should declare application requirements, whether
they are hard runtime dependencies or resource requirements. Declaring your
requirements is essential for Kubernetes to find the right place for your
application within the cluster.
Automated Placement explains how to influence
workload distribution in a multi-node cluster. Placement is the core function
of the Kubernetes scheduler for assigning new Pods to nodes satisfying
container resource requests and honoring scheduling policies. This pattern
describes the principles of Kubernetes’ scheduling algorithm and the way to
influence the placement decisions from the outside.
Having good cloud-native containers
is the first step, but not enough. Reusing containers and combining them into
Pods to achieve the desired outcome is the next step. The patterns in this
category are focused on structuring and organizing containers in a Pod to
satisfy different use cases. The forces that affect containers in Pods result
in these patterns.
Init Container introduces a separate life
cycle for initialization-related tasks and the main application containers.
Init Containers enable separation of concerns by providing a separate life
cycle for initialization-related tasks distinct from the main application containers.
This pattern introduces a fundamental Kubernetes concept that is used in many
other patterns when initialization logic is required.
Sidecar describes how to extend and
enhance the functionality of a pre-existing container without changing it. This
pattern is one of the fundamental container patterns that allows single-purpose
containers to cooperate closely together.
These patterns describe the
life-cycle guarantees of the Pods ensured by the managing platform. Depending
on the type of workload, a Pod might run until completion as a batch job or be
scheduled to run periodically. It might run as a daemon service or singleton.
Picking the right life-cycle management primitive will help you run a Pod with
the desired guarantees.
Batch Job describes how to run an
isolated, atomic unit of work until completion. This pattern is suited for
managing isolated atomic units of work in a distributed environment.
Stateful Service describes how to create and
manage distributed stateful applications with Kubernetes. Such applications
require features such as persistent identity, networking, storage, and
ordinality. The StatefulSet primitive provides these building blocks with
strong guarantees ideal for the management of stateful applications.
Service Discovery explains how clients can
access and discover the instances that are providing application services. For
this purpose, Kubernetes provides multiple mechanisms, depending on whether the
service consumers and producers are located on or off the cluster.
The patterns in this category are
more complex and represent higher-level application management patterns. Some
of the patterns here (such as Controller) are timeless, and Kubernetes itself
is built on top of them.
Controller is a pattern that actively
monitors and maintains a set of Kubernetes resources in a desired state. The
heart of Kubernetes itself consists of a fleet of controllers that regularly
watch and reconcile the current state of applications with the declared target
state. This pattern describes how to leverage this core concept for extending
the platform for our own applications.
An Operator is a Controller that uses a
CustomResourceDefinitions to encapsulate operational knowledge for a specific
application in an algorithmic and automated form. The Operator pattern allows
us to extend the Controller pattern for more flexibility and greater
expressiveness. There are an increasing number of Operators for
Kubernetes, and this pattern is turning into the major form of operating
complex distributed systems.
Today, Kubernetes is the most popular
container orchestration platform. It is jointly developed and supported by all
major software companies and offered as a service by all of the major cloud
providers. Kubernetes supports both Linux and Windows systems, plus all major
programming languages. This platform can also orchestrate and automate
stateless and stateful applications, batch jobs, periodic tasks, and serverless
workloads. The patterns described here are the most commonly used ones from a
broader set of patterns that come with Kubernetes as shown below.

Kubernetes Patters
organized in different categories
Kubernetes is the new application
portability layer and the common denominator among everybody on the cloud. If
you are a software developer or architect, the odds are that Kubernetes will
become part of your life in one form or another. Learning about the Kubernetes
patterns described here will change the way you think about this platform. I
believe that Kubernetes and the concepts originating from it will become as
fundamental as object-oriented programming concepts.
The patterns here are an attempt to
create the Gang of Four design patterns, but for container orchestration.
Reading this article must not be the end, but the beginning of your Kubernetes
journey. Happy kubectl-ing!
GraphQL based solution architecture patterns
Introduction
GraphQL is becoming popular in the tech industry as a replacement for REST. It really carries out significant advantages over existing mechanisms for the client-server type of communications. In simple terms, GraphQL allows the client to choose which information it wants rather than receiving all the data which is available for the API. This is similar to a database query where we request only the required information. That is why it is called as GraphQL. We can do this easily with databases and data services runtime. But if you think about implementing the same capability for a REST API, you have to create so many different resources and the client has to call each and every one of these resources and handle the orchestration logic at the client-side. Otherwise, the API server has to do the heavy-lifting of orchestration. But this is not scalable with the changing demands from customers and the business. You can find a simple example and an explanation of why GraphQL is considered as the better REST by reading the content in the below link.
https://www.howtographql.com/basics/1-graphql-is-the-better-rest
The intention of this post is to discuss possible solution architecture patterns that can be used to implement systems with GraphQL.
Solution Architecture Patterns
Pattern 1 — GraphQL Server exposing database
This is the fundamental use case of the GraphQL. That is to expose a database in a much more controlled manner with additional capabilities like caching. A similar kind of functionality can be achieved with the OData specification. But GraphQL has really excelled beyond the OData by giving users to do basic CRUD operations as well as allowing the consumers to subscribe to data changes. It has clearly separated out the read operations (Queries) from the write operation (Mutations) and introduced a new operation type for data change notifications through Subscriptions.
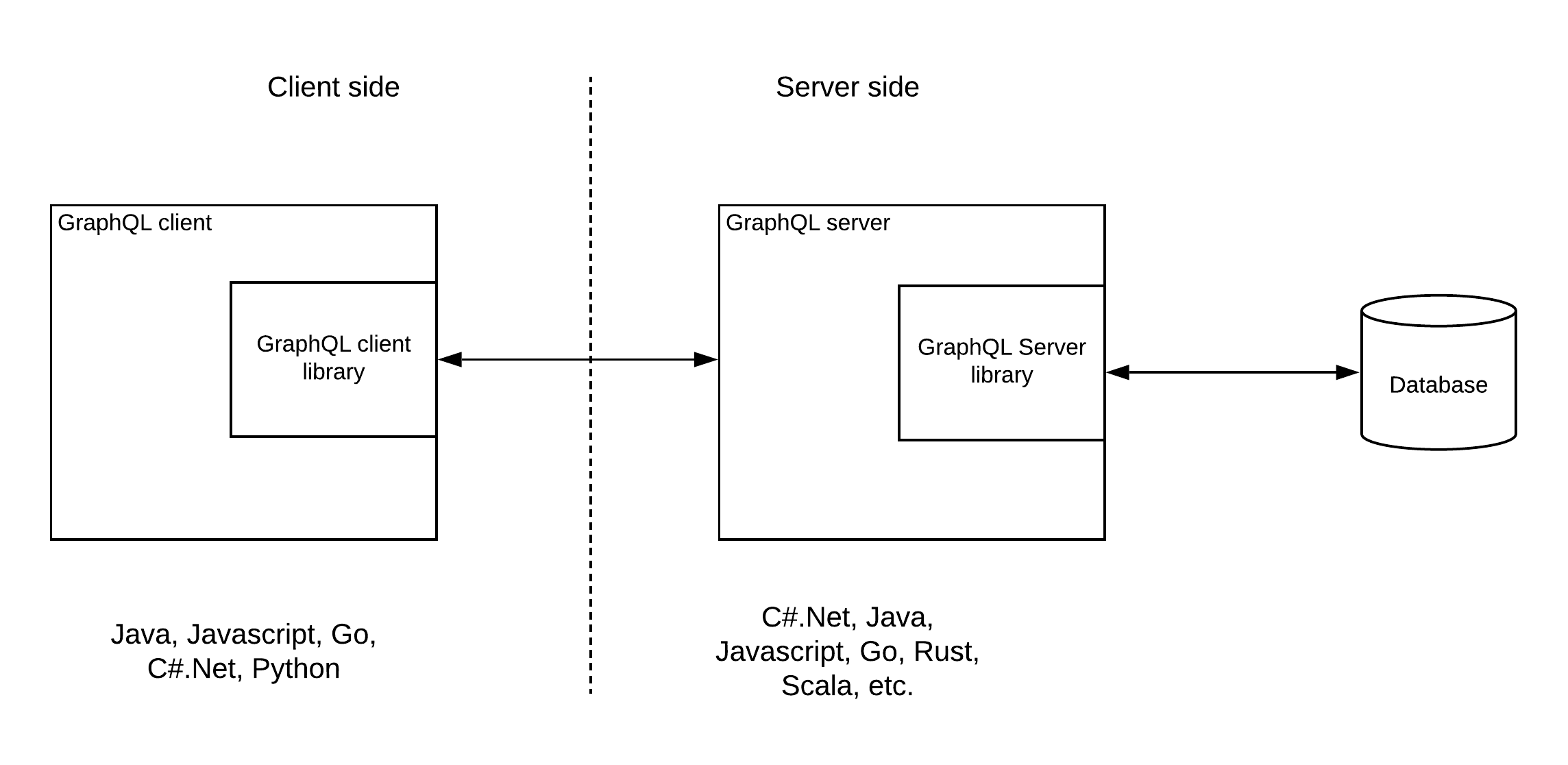 Pattern 1 — GraphQL server exposing a database
Pattern 1 — GraphQL server exposing a database
As depicted in the above figure, GraphQL provides server libraries for multiple programming languages so that developers can build servers based on GraphQL specification. You can find more details on available language support for the server-side from here. Similarly, it provides client libraries to implement GraphQL clients. More details can be found here. GraphQL server exposes a simple HTTP/REST interface so that users can use any existing tools and clients which they have already built.
Pattern 2 — GraphQL as a layer of integration
The real power of the GraphQL specification comes from the ability to provide access to various data sources from the clients in one go. Instead of sending multiple requests (and hence wasting the bandwidth due to headers), GraphQL client can send a single request and get all the data it requires regardless of the actual backend data source. This allows the GraphQL server to act as an integration hub while exposing the services through GraphQL.
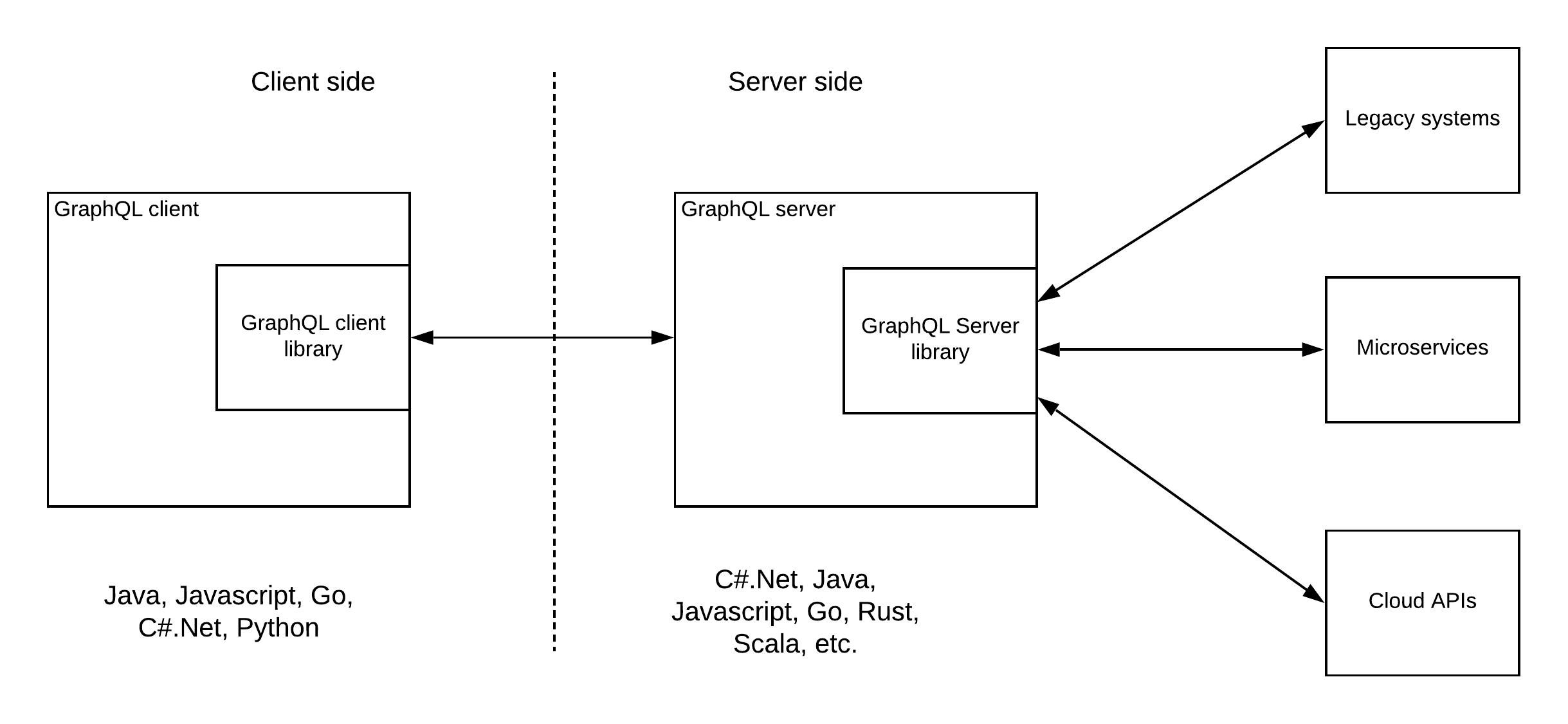 Pattern 2 — GraphQL server as an integration hub As shown in the above figure, GQL server can connect to multiple backend systems within the enterprise including legacy systems, microservices, and existing 3rd party cloud APIs as data sources and provide a unified GraphQL interface to the clients.
Pattern 2 — GraphQL server as an integration hub As shown in the above figure, GQL server can connect to multiple backend systems within the enterprise including legacy systems, microservices, and existing 3rd party cloud APIs as data sources and provide a unified GraphQL interface to the clients.
Pattern 3 — GraphQL hybrid integration
In most of the real-world scenarios, you find there are various systems that need to be connected including databases, legacy apps, microservices, cloud APIs, etc. Therefore, building a GraphQL server that connects to a database as well as other systems can be a more frequent requirement.
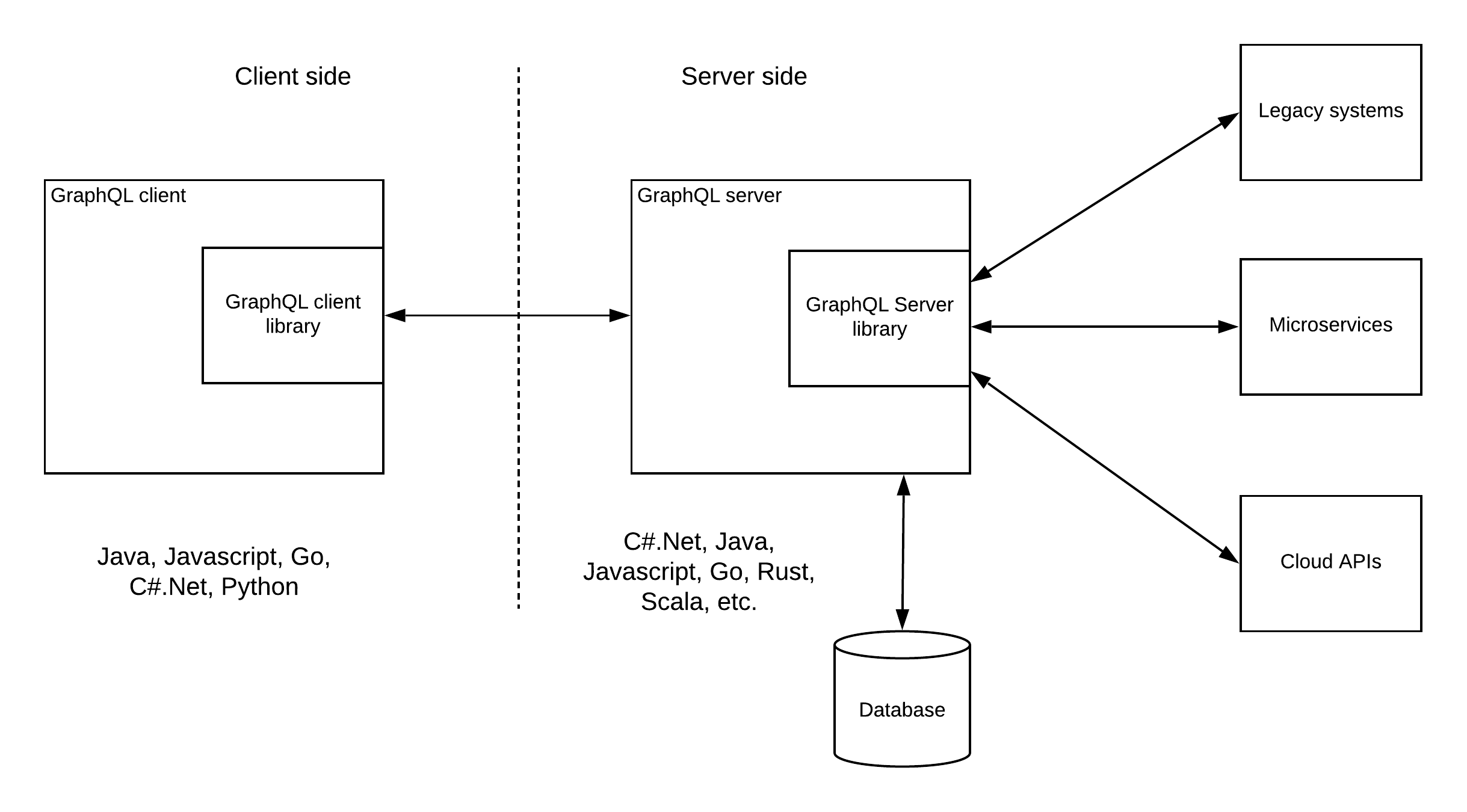 Pattern 3 — GraphQL hybrid integration In this pattern, GraphQL server has its own connected database and it will also connect to external systems. The clients get a unified API that they can consume efficiently without sending multiple requests to get desired data. The above 3 patterns are the standard GraphQL patterns recommended by the GraphQL community. But these patterns don’t fulfill the requirements of a modern enterprise architecture. The interfaces that expose these services need to be managed through a management layer. That is where the API gateways come into the picture.
Pattern 3 — GraphQL hybrid integration In this pattern, GraphQL server has its own connected database and it will also connect to external systems. The clients get a unified API that they can consume efficiently without sending multiple requests to get desired data. The above 3 patterns are the standard GraphQL patterns recommended by the GraphQL community. But these patterns don’t fulfill the requirements of a modern enterprise architecture. The interfaces that expose these services need to be managed through a management layer. That is where the API gateways come into the picture.
Pattern 4 — GraphQL server with one managed API
Exposing the GraphQL based interfaces without any security can be a big issue in most of the enterprise deployments. That is the reason why we need to apply proper protection to these APIs using an API gateway. GraphQL provides a single endpoint to access data and execute various actions on top of that data. Therefore, the simplest approach to protect and manage this interface is by applying the management functionalities over this single endpoint.
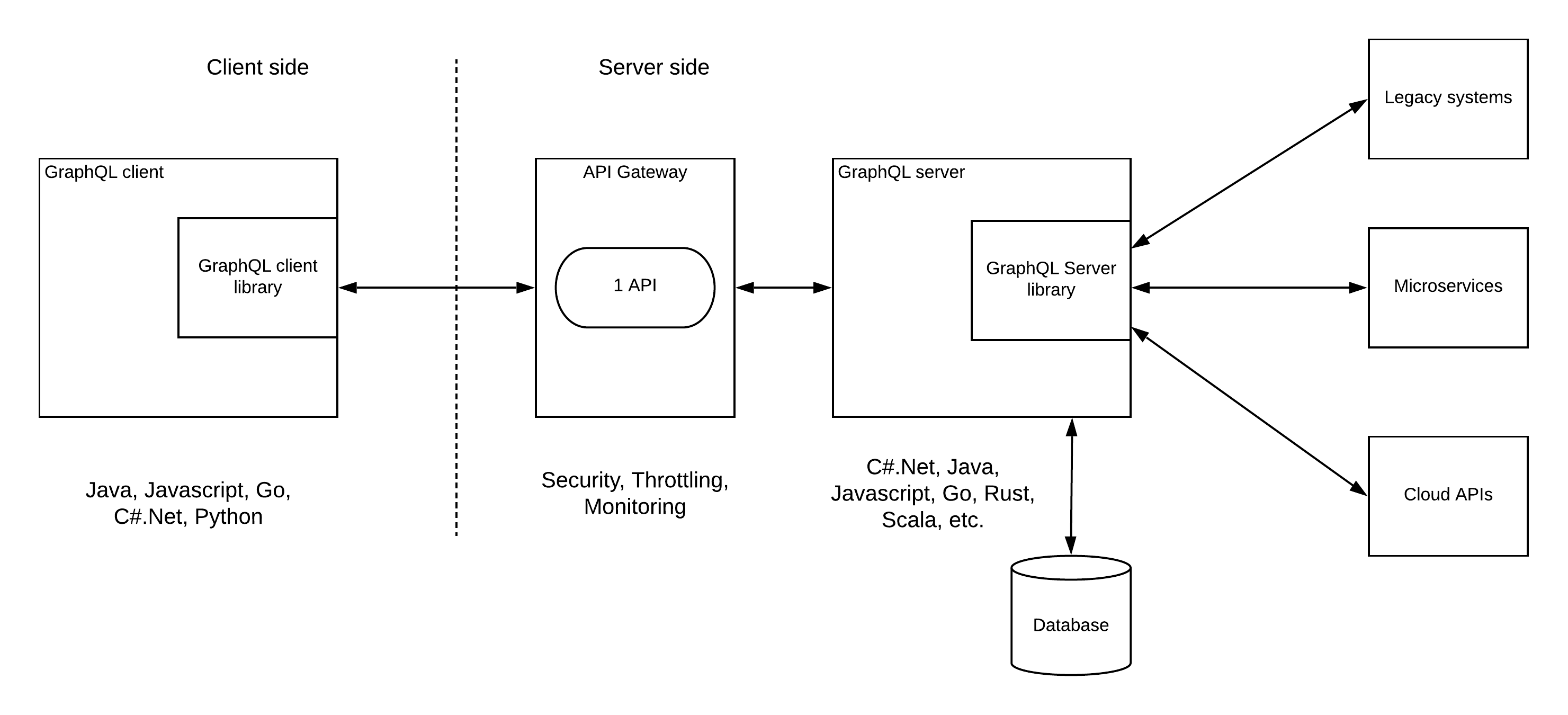 Pattern 4 — GraphQL server with one managed API In this architecture, API gateway provides the security, throttling and monitoring capabilities to the single endpoint which is exposed from the GQL server. If you have multiple GraphQL endpoints available, these endpoints can be protected as separate APIs. Also, with this approach, multiple resources can be implemented for the same API with different throttling and security policies. But this needs to be done as a custom implementation and a lot of manual work needs to be done.
Pattern 4 — GraphQL server with one managed API In this architecture, API gateway provides the security, throttling and monitoring capabilities to the single endpoint which is exposed from the GQL server. If you have multiple GraphQL endpoints available, these endpoints can be protected as separate APIs. Also, with this approach, multiple resources can be implemented for the same API with different throttling and security policies. But this needs to be done as a custom implementation and a lot of manual work needs to be done.
Pattern 5 — GraphQL server with native API management
One of the drawbacks of the above pattern 4 was that GraphQL native concepts (Queries, Mutations, Subscriptions) cannot be managed as separate entities. That is the exact requirement covered with this pattern. Here, once the GraphQL endpoint is provided to the API gateway, it will generate the GraphQL specific endpoints (operations) based on the definition of the GQL file and allow the users to apply throttling, security, and monitoring at these operations level.
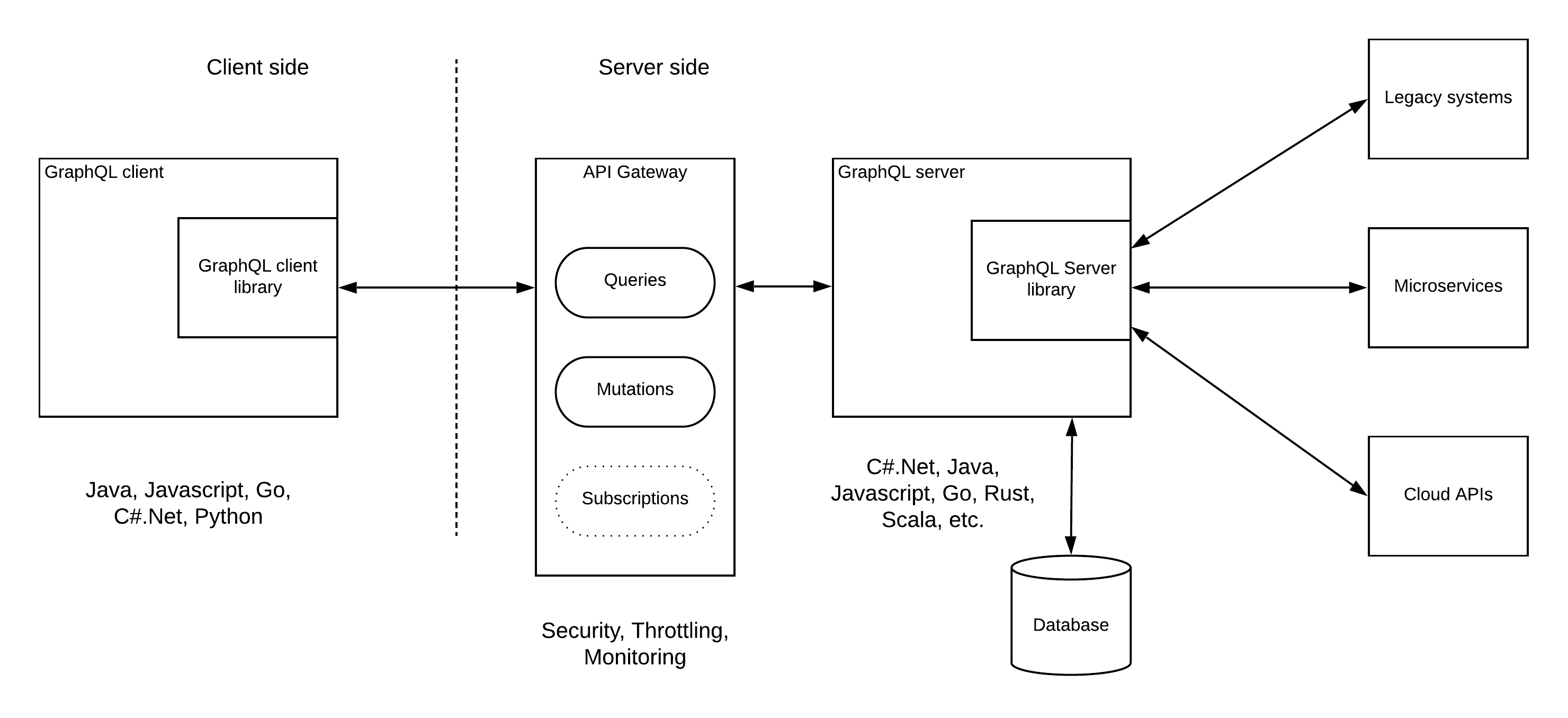 Pattern 5 — GraphQL server with native API management In this pattern, both Queries and Mutations can be implemented with native API management capabilities like security, throttling, caching, monitoring, etc. But the subscription feature of the GQL server cannot be implemented with that functionality since it works in an asynchronous, event-based mechanism.
Pattern 5 — GraphQL server with native API management In this pattern, both Queries and Mutations can be implemented with native API management capabilities like security, throttling, caching, monitoring, etc. But the subscription feature of the GQL server cannot be implemented with that functionality since it works in an asynchronous, event-based mechanism.
Implementation approach
GraphQL servers and clients can be implemented in many different programming languages and there are libraries that are purpose-built for certain technology stacks available in the community. For adding the API management capabilities, users can use existing API management tools like WSO2 API Manager which supports both the above-mentioned pattern 4 as well as pattern 5.
Future
I have discussed some of the possible solution architecture patterns with the GraphQL specification. These are not the only patterns and there can be more and more patterns evolved with the time. Additionally, the above patterns didn’t cover the container-based, cloud-native architecture patterns since that is too much of a scope for a single article. But the concepts mentioned in this article can be reused when building such architectures as well. This article is more or less a foundation article on building real-world systems with GraphQL specification.
Subscribe to:
Posts (Atom)
Scalable application Design - Example app EasyWin
In this application design important design consideration discussed mainly to make sure at least 1k concurrent users can use this app and a...

-
Ref:https://aws.amazon.com/blogs/mobile/backends-for-frontends-pattern/ Interesting points and differnt approch to design BFF: AWS AppSync ...
-
Can you design Netflix in 45 minutes? What??? Are you serious ?? (I can watch it for the whole night, but…). It’s impossible to explain even...
-
Most of the examples we saw are Client server interaction in sync or async way so that each request will be processed and result displayed ...


